Лабораторная работа № 5
Определения объема памяти для структур данных
Цель работы: изучение основных принципов распределения памяти, ознакомление с алгоритмами расчета объема памяти, занимаемой простыми и составными структурами данных, получение практических навыков создания простейшего анализатора для расчета объема памяти, занимаемого заданной структурой данных.
Для выполнения лабораторной работы требуется написать программу, которая анализирует текст входной программы, содержащий описания типов данных и переменных, и рассчитывает объем памяти, требуемый для размещения всех переменных, описанных во входной программе. Все переменные в исходной программе считаются статическими глобальными переменными. Результатом работы программы является значение требуемого объема памяти в байтах с учетом фрагментации памяти и без учета ее (объем памяти для скалярных типов данных и коэффициент фрагментации даются в задании). Текст на входном языке задается в виде символьного (текстового) файла. Программа должна выдавать сообщения о наличие во входном тексте ошибок, если структура входной программы не соответствует заданию.
Длину идентификаторов и строковых констант считать ограниченной 32 символами. Программа должна допускать наличие комментариев неограниченной длины во входном файле. Форму организации комментариев предлагается выбрать самостоятельно.
Краткие теоретические сведения
Принципы распределения памяти
Распределение памяти — это процесс, который ставит в соответствие лексическим единицам исходной программы адрес, размер и атрибуты области памяти, необходимой для этой лексической единицы. Область памяти — это блок ячеек памяти, выделяемый для данных, каким-то образом объединенных логически. Логика таких объединений задается семантикой исходного языка.
Распределение памяти работает с лексическими единицами языка — переменными, константами, функциями и т. п. — и с информацией об этих единицах, полученной на этапах лексического и синтаксического анализа. Как правило, исходными данными для процесса распределения памяти в компиляторе служат таблица идентификаторов, построенная лексическим анализатором, и декларативная часть программы («область описаний»), полученная в результате синтаксического анализа. Не во всех языках программирования декларативная часть программы присутствует явно, некоторые языки предусматривают дополнительные семантические правила для описания констант и переменных; кроме того, перед распределением памяти надо выполнить идентификацию лексических единиц языка. Поэтому распределение памяти выполняется уже после семантического анализа текста исходной программы.
Процесс распределения памяти в современных компиляторах, как правило, работает с относительными, а не абсолютными адресами ячеек памяти. Распределение памяти выполняется перед генерацией кода результирующей программы, потому что его результаты должны быть использованы в процессе генерации кода.
Каждую область памяти можно классифицировать по двум параметрам: в зависимости от ее роли в результирующей программе и в зависимости от способа ее распределения в ходе выполнения результирующей программы.
По роли области памяти в результирующей программе она бывает глобальная или локальная.
Рис. 7. Область памяти в зависимости от ее роли и способа распределения
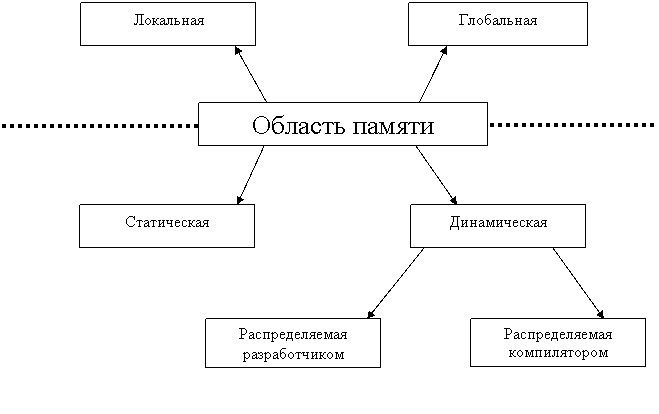
По способам распределения область памяти бывает статическая или динамическая. Динамическая память, в свою очередь, может
распределяться либо разработчиком исходной программы (по командам
разработчика), либо компилятором (автоматически).
Классификация областей памяти представлена на рис. 7.
Далеко не все лексические единицы языка требуют для себя выделения памяти. То, под какие элементы языка нужно выделять области памяти, а под какие нет, определяется исключительно реализацией компилятора и архитектурой целевой вычислительной системы. Так, целочисленные константы можно разместить в статической памяти, а можно непосредственно в тексте результирующей программы (это позволяют практически все современные вычислительные системы), то же самое относится и к константам с плавающей точкой, но их размещение в тексте программы допустимо не всегда. Кроме того, в целях экономии памяти, занимаемой результирующей программой, под различные элементы языка компилятор может выделить одни и те же ячейки памяти. Например, в одной и той же области памяти могут быть размещены одинаковые строковые константы или две различные локальные переменные, которые никогда не используются одновременно.
Виды переменных и областей памяти
Распределение памяти для переменных скалярных типов
Во всех языках программирования существует понятие так называемых «базовых типов данных», которые также называют основными или скалярными типами. Размер области памяти, необходимый для лексической единицы скалярного типа, считается заранее известным. Он определяется семантикой языка и архитектурой целевой вычислительной системы.
Например, в языке программирования C базовыми типами данных являются типы char, int, long int и т. п. (реально этих типов, конечно, больше, чем три), а в языке программирования Pascal — типы byte, char, word, integer и т. п.. Размер базового типа int в языке C для архитектуры компьютера на базе 16-разрядных процессоров составляет 2 байта, а для 32-разрядных процессоров — 4 байта. Разработчики исходной программы на этом языке, конечно, могут узнать данную информацию, но если ее использовать в исходной программе напрямую, то такая программа будет жестко привязана к конкретной архитектуре целевой вычислительной системы. Чтобы исключить эту зависимость, лучше использовать механизм определения размера памяти для типа данных, предоставляемый языком программирования — в языке C это функция sizeof.
Распределение памяти для сложных структур данных
Для более сложных структур данных используются правила распределения памяти, определяемые семантикой (смыслом) этих структур. Эти правила достаточно просты и, в принципе, одинаковы во всех языках программирования.
Вот правила распределения памяти под основные виды структур данных:
- для массивов — произведение числа элементов в массиве на размер памяти для одного элемента (то же правило применимо и для строк, но во многих языках строки содержат еще и дополнительную служебную информацию фиксированного объема);
- для структур (записей с именованными полями) — сумма размеров памяти по всем полям структуры;
- для объединений (союзов, общих областей, записей с вариантами) — размер максимального поля в объединении;
- для реализации объектов (классов) — размер памяти для структуры с такими же именованными полями плюс память под служебную информацию объектно-ориентированного языка (как правило, фиксированного объема).
Формулы для вычисления объема памяти можно записать следующим образом:
для массивов: Vмас = Õi=1,n(mi) * Vэл,
где n — размерность массива, mi — количество элементов i-ой размерности, Vэл — объем памяти для одного элемента;
для структур: Vстр = Si=1,nVполяi,
где n — общее количество полей в структуре, Vполяi — объем памяти для i-го поля структуры;
для объединений: Vстр = maxi=1,nVполяi,
где n — общее количество полей в объединении, Vполяi — объем памяти для i-го поля объединения.
Для более сложных структур данных входного языка объем памяти, отводимой под эти структуры данных, вычисляется рекурсивно. Например, если имеется массив структур, то при вычислении объема отводимой под этот массив памяти для вычисления объема памяти, необходимой для одного элемента массива, будет вызвана процедура вычисления памяти структуры. Такой подход определения объема занимаемой памяти очень удобен, если декларативная часть языка представлена в виде дерева типов. Тогда для вычисления объема памяти, занимаемой типом из каждой вершины дерева, нужно вычислить объем памяти для всех потомков этой вершины, а потом применить формулу, связанную непосредственно с самой вершиной (этот механизм подобен механизму СУ-перевода, применяемому при генерации кода). Как раз такого типа древовидные конструкции строит синтаксический анализ для декларативной части языка.
Например, если рассмотреть фрагмент текста входной программы на языке Pascal:
...
type
arr1 = array[1..10,1..20] of
integer;
rec1 = record
v1: word;
a1: arr1;
end;
rec2 = record
v1: byte;
case (v2: integer) of
0: v3: byte;
1: v4: word;
3: v5: integer;
end;
arr2 = array[1..100] of rec2;
var
aa1: arr1;
vv1,vv2,vv3,vv4: byte;
rr1: rec1;
aa2arr2;
...
Тогда, если известно, что размер скалярных типов данных byte, word и integer составляет для целевой вычислительной системы 1, 2 и 4 байта соответственно, то можно посчитать, что размер типа arr1 будет составлять V1 = 10*20*4 = 800 байт, размер типа rec1 составит V2 = 2+800 = 802 байта, размер типа rec2 составит V3 = 1+4+Max(1,2,4) = 9 байт, а размер типа arr2 составит V4 = 100*9 = 900 байт. Тогда для размещения переменной aa1 потребуется 800 байт памяти, для размещения переменных vv1,vv2,vv3,vv4 потребуется 4 байта памяти, для переменной rr1 – 802 байта, а для переменной aa2 – еще 900 байт. Таким образом, для размещения в памяти всей описанной структуры данных потребуется выделить V = 2506 байт памяти.
Выравнивание границ областей памяти
Говоря об объеме памяти, занимаемой различными лексическими единицами и структурами данных языка, следует упомянуть еще один момент – выравнивание границ областей памяти, отводимых для различных лексических единиц.
Архитектура многих современных вычислительных систем предусматривает, что обработка данных выполняется более эффективно, если адрес, по которому выбираются данные, кратен определенному числу байт (как правило, это 2, 4, 8 или 16 байт). Современные компиляторы учитывают особенности целевых вычислительных систем. При распределении данных они могут размещать области памяти под лексические единицы наиболее оптимальным образом. Поскольку не всегда размер памяти, отводимой под лексическую единицу, кратен указанному числу байт, то в общем объеме памяти, отводимой под результирующую программу, могут появляться неиспользуемые области.
Например, если мы имеем описание переменных на языке C:
static
char c1, c2, c3;
то, зная, что под одну переменную типа char отводится 1 байт памяти, можем ожидать, что для описанных выше переменных потребуется всего 3 байта памяти. Однако если кратность адресов для доступа к памяти установлена 4 байта, то под эти переменные будет отведено в целом 12 байт памяти, из которых 9 не будут использоваться.
Выравнивание границ областей памяти возможно как по границам структур данных (и представляющих их лексем), так и внутри самих структур данных для составляющих их элементов. Например, если мы имеем описание массивов на языке Pascal:
a1,a2: array[1..3] of char;
то при условии, что под одну переменную типа char отводится 1 байт памяти и кратность адресов установлена 4 байта, в случае, когда выравнивание границ областей памяти выполняется только по границам самих областей, под описанные выше переменные потребуется 8 байт памяти (по 4 байта на каждый массив). Если же выравнивание границ областей памяти выполняется и для составляющих элементов (в данном случае – элементов массивов), то под эти же переменные потребуется 24 байта памяти (по 4 байта на один элемент массива – и в целом 12 байт на каждый массив).
Как правило, разработчику исходной программы не нужно знать, каким образом компилятор распределяет адреса под отводимые области памяти. Чаще всего компилятор сам выбирает оптимальный метод, и, изменяя границы выделенных областей, он всегда корректно осуществляет доступ к ним. Вопрос об этом может встать, если с данными программы, написанной на одном языке, работают программы, написанные на другом языке программирования (чаще всего, на языке ассемблера), реже такие проблемы возникают при использовании двух различных компиляторов с одного и того же входного языка. Большинство компиляторов позволяют пользователю в этом случае самому указать, использовать или нет кратные адреса и какую границу кратности установить (если это вообще возможно с точки зрения архитектуры целевой вычислительной системы).
Если вернуться к рассмотренному выше примеру фрагмента программы на языке Pascal, то, если предположить, что кратность размещения данных в целевой вычислительной системе составляет 4 байта и выравнивание границ памяти выполняется только по границам структур, можно рассчитать новые значения объема памяти, требуемой для размещения описанных в этом фрагменте переменных.
Размер типа arr1 будет составлять V1 = 10*20*4 = 800 байт. Размер типа rec1 составит V2 = 2+800 = 802 байта, но с учетом кратности (4 байта) для его размещения потребуется V2' = 4+800 = 804 байта. Размер типа rec2 V3 = 1+4+Max(1,2,4) = 9 байт с учетом кратности составит V3' = 12 байт, а размер типа arr2 с учетом кратности составит V4' = 100*12 = 1200 байт. Тогда для размещения переменной aa1 потребуется 800 байт памяти, для размещения переменных vv1,vv2,vv3,vv4 с учетом кратности потребуется 4*4 = 16 байт памяти, для переменной rr1 – 804 байта, а для переменной aa2 – еще 1200 байт. Таким образом, для размещения в памяти всей описанной структуры данных потребуется выделить V' = 2820 байт памяти.
При тех же условиях, но с выравниванием границ памяти по элементам структур, необходимые объемы памяти в данном случае не изменятся. Размер типа arr1 будет составлять V1 = 10*20*4 = 800 байт. Размер типа rec1 с учетом кратности составит V2" = 4+800 = 804 байта. Размер типа rec2 с учетом кратности составит V3' = 4+4+Max(4,4,4) = 12 байт, а размер типа arr2 с учетом кратности составит V4' = 100*12 = 1200 байт.
Видно, что объем требуемой памяти в обоих случаях увеличился примерно на 12.5%, но за счет этого увеличивается эффективность обращения к данным и, следовательно, скорость выполнения результирующей программы.
Виды областей памяти. Статическое и динамическое связывание
Глобальная и локальная память
Глобальная область памяти — это область памяти, которая выделяется один раз при инициализации результирующей программы и действует все время выполнения результирующей программы.
Как правило, глобальная область памяти может быть доступна из любой части исходной программы, но многие языки программирования позволяют налагать синтаксические и семантические ограничения на доступность даже для глобальных областей памяти. При этом сами области памяти и связанные с ними лексические единицы остаются глобальными, ограничения налагаются только на возможность их использования в тексте исходной программы (и эти ограничения, в принципе, возможно обойти).
Локальная область памяти — это область памяти, которая выделяется в начале выполнения некоторого фрагмента результирующей программы (блока, функции, процедуры или оператора) и может быть освобождена по завершении выполнения данного фрагмента.
Доступ к локальной области памяти всегда запрещен за пределами того фрагмента программы, в котором она выделяется. Это определяется как синтаксическими и семантическими правилами языка, так и кодом результирующей программы. Даже если удастся обойти ограничения, налагаемые входным языком, использование таких областей памяти вне их области видимости приведет к катастрофическим последствиям для результирующей программы.
Распределение памяти на локальные и глобальные области целиком определяется семантикой языка исходной программы. Только зная смысл синтаксических конструкций исходного языка можно четко сказать, какая из них будет отнесена в глобальную область памяти, а какая — в локальную.
Рассмотрим для примера фрагмент текста модуля программы на языке Pascal:
...
const
Global_1 = 1;
Global_2 : integer = 2;
var
Global_I : integer;
...
function Test (Param: integer):
pointer;
const
Local_1 = 1;
Local_2 : integer = 2;
var
Local_I : integer;
begin
...
end;
Согласно семантике языка Pascal, переменная Global_I является глобальной переменной языка и размещается в глобальной области памяти, константа Global_1 также является глобальной, но язык не требует, чтобы компилятор обязательно размещал ее в памяти — значение константы может быть непосредственно подставлено в код результирующей программы там, где она используется. Типизированная константа Global_2 является глобальной, но в отличие от константы Global_1, семантика языка предполагает, что эта константа обязательно будет размещена в памяти, а не в коде программы. Доступность идентификаторов Global_I, Global_2 и Global_1 из других модулей зависит от того, где и как они описаны. Например, для компилятора Borland Pascal переменные и константы, описанные в заголовке модулей, доступны из других модулей программы, а переменные и константы, описанные в теле модулей, недоступны, хотя и те и другие являются глобальными.
Параметр Param функции Test, переменная Local_I и константа Local_1 являются локальными элементами этой функции. Они не доступны вне пределов данной функции и располагаются в локальной области памяти. Типизированная константа Local_2 представляет собой очень интересный элемент программы. С одной стороны, она не доступна вне пределов функции Test и потому является ее локальным элементом. С другой стороны, как типизированная константа она будет располагаться в глобальной области памяти, хотя ниоткуда извне не может быть доступна (аналогичными конструкциями языка C, например, являются локальные переменные функций, описанные как static).
Семантические особенности языка должны учитывать создатели компилятора, когда разрабатывают модуль распределения памяти. Безусловно, это должен знать и разработчик исходной программы, чтобы не допускать семантических (смысловых) ошибок — этот тип ошибок сложнее всего поддается обнаружению.
Статическая и динамическая память
Статическая область памяти — это область памяти, размер которой известен на этапе компиляции.
Поскольку для статической области памяти известен ее размер, компилятор всегда может выделить эту область памяти и связать ее с соответствующим элементом программы. Поэтому для статической области памяти компилятор порождает некоторый адрес (как правило, это относительный адрес в программе). Статические области памяти обрабатываются компилятором самым простейшим образом, поскольку напрямую связаны со своим адресом. В этом случае говорят о статическом связывании области памяти и лексической единицы входного языка.
Динамическая область памяти — это область памяти, размер которой на этапе компиляции программы не известен.
Размер динамической области памяти будет известен только в процессе выполнения результирующей программы. Поэтому для динамической области памяти компилятор не может непосредственно выделить адрес — для нее он порождает фрагмент кода, который отвечает за распределение памяти (ее выделение и освобождение). Как правило, с динамическими областями памяти связаны многие операции с указателями и с экземплярами объектов (классов) в объектно-ориентированных языках программирования. При использовании динамических областей памяти говорят о динамическом связывании области памяти и лексической единицы входного языка.
Динамические области памяти, в свою очередь, можно разделить на динамические области памяти, выделяемые пользователем, и динамические области памяти, выделяемые непосредственно компилятором.
Динамические области памяти, выделяемые пользователем, появляются в тех случаях, когда разработчик исходной программы явно использует в тексте программы функции, связанные с распределением памяти (примером таких функций являются New и Dispose в языке Pascal, malloc и free в языке C, new и delete в языке C++ и другие). Функции распределения памяти могут использовать либо напрямую средства ОС, либо средства исходного языка (которые, в конце концов, все равно основаны на средствах ОС). В этом случае за своевременное выделение и освобождение памяти отвечает сам разработчик, а не компилятор. Компилятор должен только построить код вызова соответствующих функций и сохранения результата — в принципе, для него работа с динамической памятью пользователя ничем не отличается от работы с любыми другими функциями и дополнительных сложностей не вызывает.
Другое дело — динамические области памяти, выделяемые компилятором. Они появляются тогда, когда пользователь использует типы данных, операции над которыми предполагают перераспределение памяти, не присутствующее в явном виде в тексте исходной программы. Примерами таких типов данных могут служить строки в некоторых языках программирования, динамические массивы и, конечно, многие операции над экземплярами объектов (классов) в объектно-ориентированных языках (наиболее характерный пример — тип данных string в Borland Delphi). В этом случае сам компилятор отвечает за порождение кода, который будет всегда обеспечивать своевременное выделение памяти под элементы программы и за освобождение ее по мере использования.
Как статические, так и динамические области памяти сами по себе могут быть глобальными или локальными.
Порядок выполнения работы
- Получить вариант задания у преподавателя.
- Построить распознаватель для входной программы на основе заданной грамматики.
- Изучить алгоритм расчета требуемого объема памяти для структур данных входной программы.
- Разработать фрагменты объектного кода, реализующие на языке ассемблера простейшие операции в заданной грамматике.
- Реализовать алгоритм расчета объема требуемой памяти на основе результатов синтаксического анализа.
- Выполнить расчет требуемого объема памяти для выбранного простейшего примера. Проверить корректность результата.
- Подготовить и защитить отчет.
- Написать и отладить программу на ЭВМ.
Требования к оформлению отчета
Отчет должен содержать следующие разделы:
· Задание по лабораторной работе.
· Краткое изложение цели работы.
· Запись заданной грамматики входного языка в форме Бэкуса-Наура.
· Описание алгоритма расчета объема памяти для структуры данных, указанной в задании.
· Пример выполнения разбора простейшей входной программы (по выбору).
· Текст программы (оформляется после выполнения программы на ЭВМ по согласованию с преподавателем).
Основные контрольные вопросы
1. Что такое распределение памяти? Какую роль оно играет в процессе компиляции?
2. Для каких элементов входной программы выполняется распределение памяти?
3. Что такое относительные адреса? В какой момент и как относительные адреса преобразуются в адреса физические?
4. Какие типы областей памяти бывают в зависимости от роли и способа распределения? Как они могут сочетаться между собой?
5. Что такое локальная и глобальная память? Как распределяется память для аргументов и локальных переменных процедур и функций?
6. Что такое динамическая и статическая память? Какие особенности можно указать для динамической памяти, распределяемой компилятором?
7. Приведите примеры локальных и глобальных, статических и динамических элементов памяти на основе известного Вам языка программирования.
8. Что такое скалярные типы данных? От чего зависит объем памяти, выделяемой для скалярных типов данных?
9. Как рассчитывается объем памяти для сложных структур данных?
10.Что такое «кратность распределения памяти»? Для чего она используется?
11.Как влияет кратность распределения памяти на объем памяти, требуемой для различных структур данных? Приведите примеры.
12.Что такое дисплей памяти процедуры или функции? Расскажите о стековой организации дисплея памяти.
Варианты исходных грамматик
Во всех вариантах используется одна и та же грамматика входного языка. Входная программа представляет собой последовательность двух блоков: первый блок – описание типов, начинающееся с ключевого слова type, второй блок – описание переменных, начинающееся с ключевого слова var. Описание типов и описание переменных выполняется в стиле языка Pascal.
Необходимо разобрать описания всех типов, рассчитать объем для каждого типа данных на основе известных алгоритмов и размеров скалярных типов данных, указанных в задании. Расчет надо выполнить в двух случаях: с учетом кратности распределения памяти и без него. Затем на основе рассчитанных размеров типов данных необходимо рассчитать объем памяти, занимаемой всеми описанными переменными (расчет также должен выполняться в двух вариантах: с учетом кратности распределения памяти и без него). Результатом выполнения программы должны быть две величины: размер памяти, требуемой для всех описанных переменных, с учетом кратности распределения и тот же самый размер без учета кратности распределения.
Во всех вариантах символ S является начальным символом грамматики; L, T, R, V, K, D, F и E обозначают нетерминальные символы. Терминальные символы выделены жирным шрифтом. Терминальный символ c соответствует одному из двух скалярных типов, указанных в задании. Терминальный символ t соответствует одному из типов данных, который может быть описан в секции type, а терминальный символ a соответствует переменным, которые могут быть описаны в секции var. Терминальный символ d соответствует любой целочисленной константе. Грамматики в заданиях отличаются только правилами для терминальных символов D, F и E, которые описывают вариант допустимых типов данных – возможны три варианта: структура данных, союз (запись с вариантами) или массив.
Кроме расчета объема памяти программа, построенная на основе
задания, должна выполнять синтаксическую проверку и элементарный семантический
контроль входной программы – в том случае, если встречается тип данных, не
описанный в секции type,
должно выдаваться сообщение об ошибке.
Входная грамматика описаний типов для программы описывается следующими правилами:
1. S ® type
L; var R; 2. S ® type L; var R; 3. S ® type L; var R;
L
® T | L;T L
® T | L;T L ® T | L;T
T
® t=c
| t=D T ® t=c
| t=D T ® t=c | t=D
R
® V | R;V R
® V | R;V R ® V | R;V
V
® K:t
| K:c | K:D V
® K:t
| K:c | K:D V ® t:K
| c:K | D:K
K
® a |
K,a K
® a |
K,a K
® a |
K,a
D
® record F; end D ® union F; end D ® struct (F;)
F
® E | F;E F
® E | F;E F
® E | F;E
E ® K:c | K:t E ® K:c | K:t E ® c:K | t:K
4. S ® type
L; var R; 5. S ® type L; var R; 6. S ® type L; var R;
L
® T | L;T L
® T | L;T L ® T | L;T
T
® t=c
| t=D T ® t=c
| t=D T ® t=c | t=D
R
® V | R;V R
® V | R;V R ® V | R;V
V
® K:t
| K:c | K:D V
® t:K
| c:K | D:K V ® t:K
| c:K | D:K
K
® a |
K,a K
® a |
K,a K
® a |
K,a
D
® array [F] of c | array [F]
of t D ® union (F;) D ® array c (F) | array
t (F)
F
® E | F,E F
® E | F,E F
® E | F,E
E
® d..d E
® c:K | t:K E
® d
Варианты заданий
|
№ варианта |
№ варианта
грамматики |
Скалярные
типы (размер в байтах) |
Кратность
распределения памяти |
Кратность
элементов структур |
|
1 |
1 |
byte (1 байт), word (2 байта) |
2 |
Да |
|
2 |
2 |
byte (1 байт), word (2 байта) |
2 |
Да |
|
3 |
3 |
byte (1 байт), word (2 байта) |
2 |
Да |
|
4 |
4 |
char
(1 байт), integer (4 байта) |
2 |
Да |
|
5 |
5 |
char
(1 байт), integer (4 байта) |
2 |
Да |
|
6 |
6 |
char
(1 байт), integer (4 байта) |
2 |
Да |
|
7 |
1 |
byte
(1 байт), real (6 байт) |
4 |
Нет |
|
8 |
2 |
byte
(1 байт), real (6 байт) |
4 |
Нет |
|
9 |
3 |
byte
(1 байт), real (6 байт) |
4 |
Нет |
|
10 |
4 |
char
(1 байт), double (8 байт) |
4 |
Нет |
|
11 |
5 |
char
(1 байт), double (8 байт) |
4 |
Нет |
|
12 |
6 |
char
(1 байт), double (8 байт) |
4 |
Нет |
|
13 |
1 |
byte
(1 байт), extended
(10 байт) |
8 |
Да |
|
14 |
2 |
byte
(1 байт), extended (10
байт) |
8 |
Да |
|
15 |
3 |
byte
(1 байт), extended
(10 байт) |
8 |
Да |
|
16 |
4 |
integer
(4 байта), real (6 байт) |
8 |
Да |
Рекомендуемая литература
1. Молчанов А.Ю. Системное программное обеспечение. Лабораторный практикум. – СПб.: Питер, 2005 – 284 с.
2. Молчанов А.Ю. Системное программное обеспечение: Учебник для вузов. 3-е изд. — СПб.: Питер, 2010 — 400 с.
3. Свердлов С.З. Языки программирования и методы трансляции: учеб. пособие. — СПб.: Питер, 2007 — 400 с.
4. Гордеев А.В., Молчанов А.Ю. Системное программное обеспечение – СПб.: Питер, 2001 (2002) - 736 с.
5. Робин Хантер Основные концепции компиляторов – М.: Издательский дом «Вильямс», 2002 – 256 с.
6. Ахо А., Ульман Дж. Теория синтаксического анализа, перевода и компиляции - М.: Мир, 1978, т.1.
7. Грис Д. Конструирование компиляторов для цифровых вычислительных машин - М.: Мир, 1975.